

Content reuse is one of the main reasons why organizations move away from unstructured writing and introduce the Darwin Information Typing Architecture (DITA) standard. It’s a promise of freeing authors from the mundane and error-prone task of copy-pasting or from mastering the find & replace mechanism. For many, reusing content in a structured and controlled way is a dream come true.
Whether you’re considering DITA or you have already adopted it, we hope this summary is a helpful overview of the most common DITA reuse mechanisms:
- Reusing topics and groups of topics
- Reusing parts of a topic
- Reusing variable phrases
- Filtering your content
Rather watch than read? Here's a recording of our webinar: How to Reuse Structured Content With DITA.
Reusing Topics and Groups of Topics
The most basic form of reuse is using one topic in multiple deliverables. This is possible:
- When the content of a topic is identical for different audiences, products, deliverable types, and so on. In this case, you simply add the same topic in multiple maps. A good example of this type of reuse is a topic with copyright information that is identical for all deliverables your organization publishes.
- When topic content is identical, with the exception of the product name, product-specific information, or even user interface elements. In this case, you can still reuse the topic and add variables, which we’ll discuss later in this post.
To add a topic to a deliverable, you attach it to a map. To reuse a topic in multiple deliverables, you simply attach it to multiple maps. Maps are how DITA bundles a set of topics together to work with them as a group.
What is a DITA map? Here's a post explaining the Basics of DITA Maps.
Here is an example of reusing one topic in two maps. The group of Topics (blue) represents your Content Library and you can see that the Introduction, Maintenance, and Troubleshoot topics are reused in both maps.
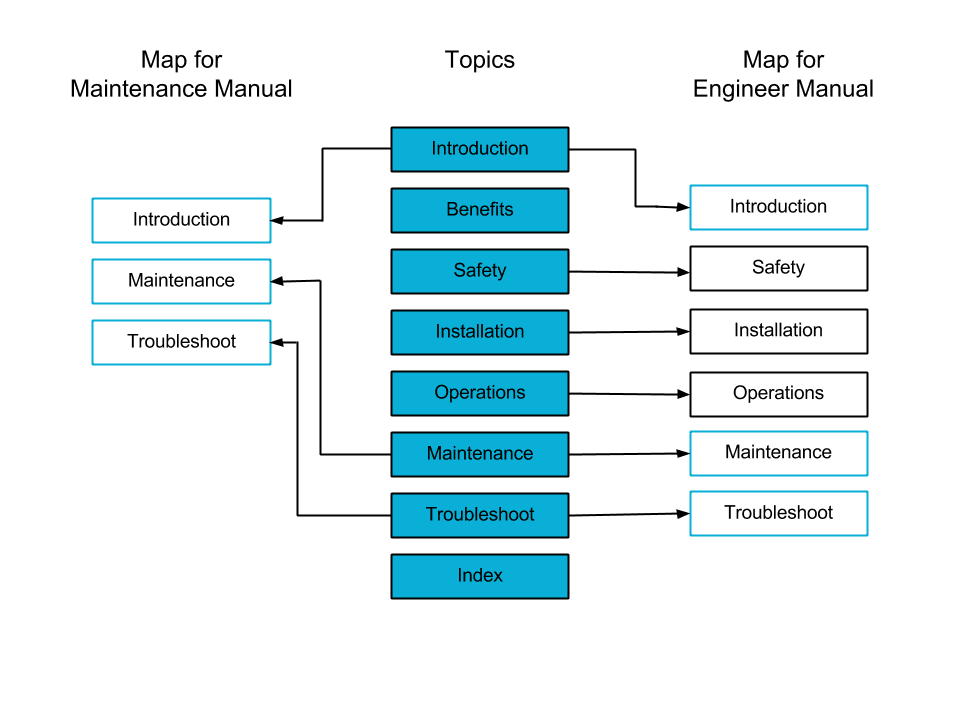
Apart from topics, you can also reuse entire maps. It’s a powerful method of reuse, for example, if you need to maintain a catalog of all product documentation and also be able to print a product deliverable independently.
How it’s done: You can reuse topics and maps directly by including a reference to a specific topic or map using a topic reference (topicref) or map reference (mapref). You can also reuse topics and maps indirectly by referring to a key value (keyref) that gets a specific definition elsewhere. It's like saying 'I'm going home', instead of saying 'I'm going to a specific address'. Your home is, of course, at a specific address. Someone else's home is at a different address. At the end of the day, you can both say 'I'm going home.'
Reusing Parts of a Topic
You can also reuse parts of topics, for example, steps or notes, by using content references (conrefs). Conrefs pull content directly from one topic into another. So, rather than copying and pasting content, you can create a warehouse topic that will work as a single source for a set of reusable topic elements and then reference them directly from those warehouse topics. Whenever you edit a reused element, you only need to do it once in your warehouse topic and your change will be applied in all topics that reference that element.
Here is an example of how you reuse steps from a warehouse topic by using conrefs. The Conref Warehouse topic contains two steps, each with a different ID. The ID is a unique identifier that is used to pull the correct content. In the Toasting Bread task topics, conrefs reference the ID of the steps from the warehouse topic and pull the steps into the task topics. When you edit the steps in the warehouse topic, your changes will be applied in both task topics. You can conref to many elements, including entire topics, topic bodies, steps, and other elements which makes it a very powerful reuse mechanism.
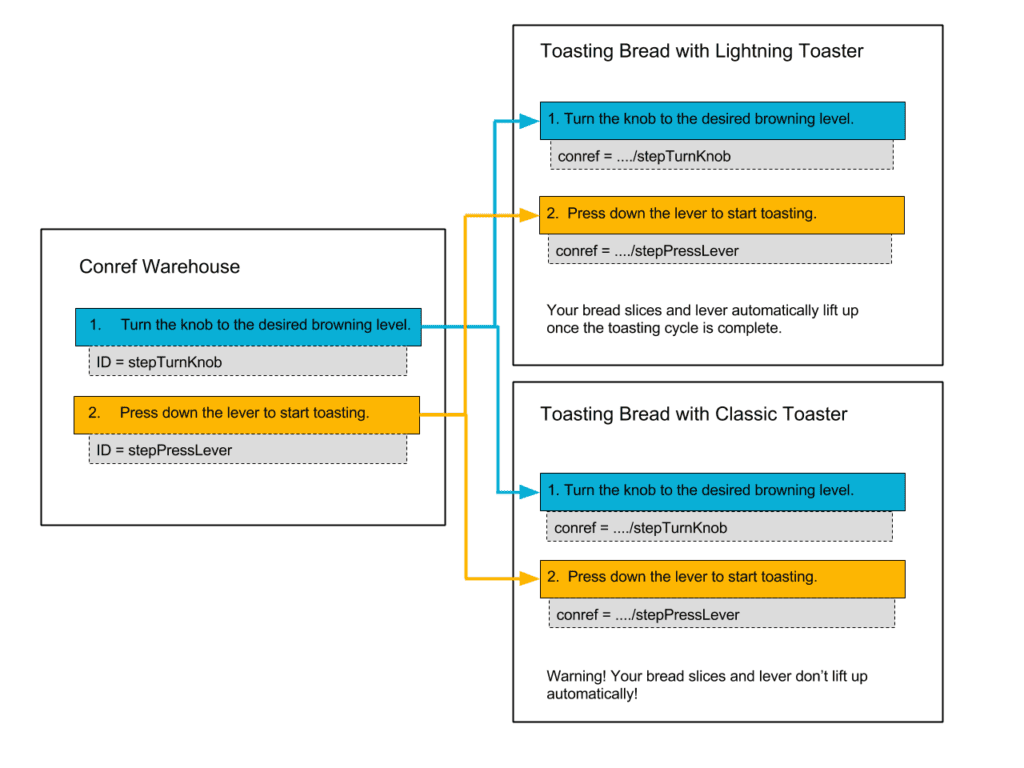
How it’s done: You can reuse content by creating conrefs to reusable elements with the conref attribute (many authoring systems, including Heretto, make this a simple point and click action, no need to work directly with the attributes). As a result, a piece of content is pulled directly from one topic into another. Deciding how, where, and when to use conref is typically covered in your organization’s content model.
Reusing Variable Phrases
Another way of reusing content is with content key references (conkeyrefs). Conkeyrefs are frequently used for variable phrases (variables), or small bits of content that might change. When you use variables, you're not actually inserting the content that's displayed, but creating an indirect reference to the content, which, again, is like saying ‘I’m going home’ rather than ‘I’m going to a specific address.’
You can use variables for information such as product names, company names, product-specific information, and even user interface elements.
A good example of using conkeyref variables is when you have two products that are very similar aside from their names or other minor parameters. With conkeyrefs, you can use one topic for both products. Product-specific information, added as variables, will change depending on the map (each map will have a different warehouse topic with variable values specific to the product but the same variable IDs).
Here is an example of two maps that reuse a Toasting Bread topic. Each map is dedicated to a different product: Classic Toaster or Lightning Toaster. Reuse of the Toasting Bread topic is possible thanks to variables added via conkeyrefs.

Each map contains a different Variables Warehouse topic with the same key attribute defined as vars. Each of the Variables Warehouse topics contains a product variable with the same ID (productName), but a different value (Classic Toaster or Lightning Toaster).
The Toasting Bread topic has a conkeyref added with the value vars/productName, which is an address to the variable element that combines the key of the Variables Warehouse topics (vars) and the product variable ID (productName). In the Toasting Bread topic, this address resolves to the variable value (Classic Toaster or Lightning Toaster) depending on which map you use the topic in. This is possible because the conkeyref uses an indirect address that combines a key and an ID instead of a direct address. The same key/ID pair can resolve to different content when the key is assigned to a different warehouse topic that uses the same set of IDs for its variables.
How it’s done: With conkeyrefs, you can reuse small bits of content that might change. You can do it by inserting conkeyrefs in your topics that point to the IDs of elements in a warehouse topic. As a result, the content of the element is pulled from the warehouse topic and displayed in your topic. The address to the variable that is used by conkeyref is indirect and, therefore, can resolve to different variable values. The value to which it resolves depends on the variable value defined in the warehouse topic. If you’re interested in an article dedicated to conkeyrefs, please let us know in the comments!
Filtering Your Content
Filtering, or conditional processing, is another mechanism for reusing content by adding attributes (let’s call them ‘tags’) to content that varies for different audiences or publications so you can filter it out when publishing. With conditional processing, you can provide targeted and personalized content to a range of users. Content for multiple conditions can exist in one topic, so you don't have to maintain multiple versions of a file. You simply need to apply 'tags' to elements to identify specific audiences or platforms the content is meant for. During publish, a DITAVal file, that contains processing conditions, controls which content is included in the output and which is excluded.
So, if you have a map that contains topics with elements that are meant only for an internal audience--for example, notes with internal-only information--you can ‘tag’ them as internal and, during the publishing process, define conditions that will exclude internal content from all customer-facing deliverables, such as a User Guide. With conditional processing, you can also control which topics are included in a publish by ‘tagging’ elements that link to topics (topicrefs) inside a map. As a result, during the publishing process, entire topics will be filtered in or out of your map based on the conditions you defined in a DITAVAL file.
Here is an example of a topic with conditional processing applied. The Classic Toaster Introduction topic contains some content meant for users and a note meant for internal testers. During publish, the DITAVal for customer-facing outputs will exclude from the output all content that is ‘tagged’ as internal. As a result, the published User Guide doesn’t contain the internal note in the Classic Toaster Introduction topic.
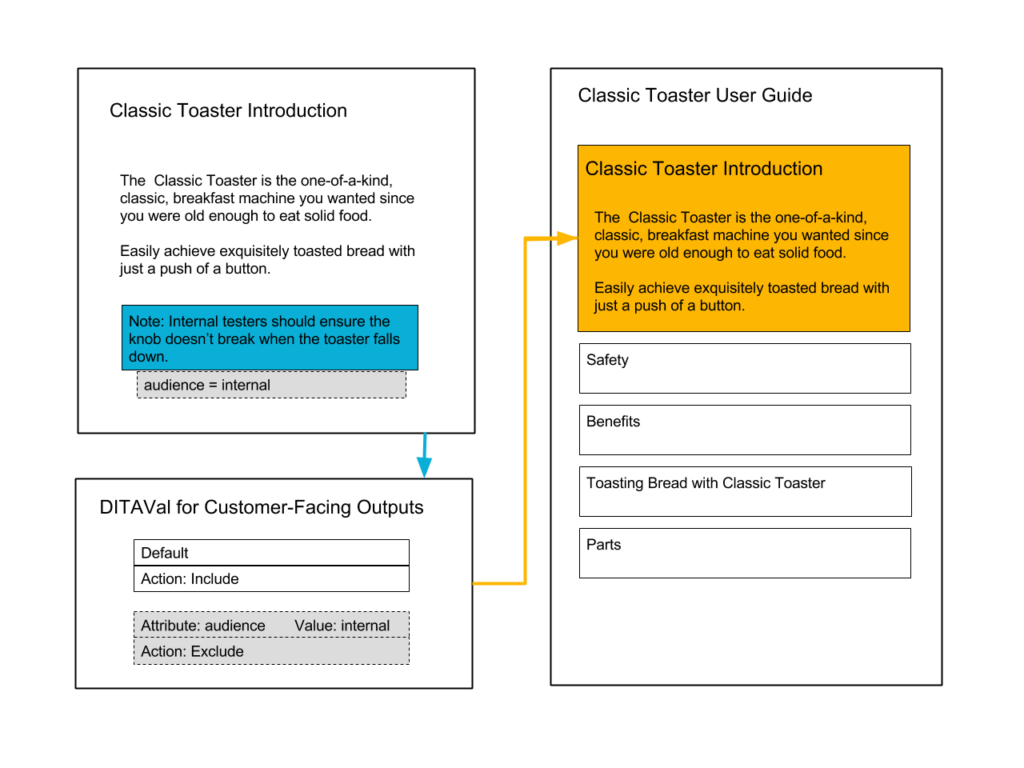
How it’s done: You ‘tag’ your content by defining conditional processing attributes, including Audience, Platform, Product, and Other Props. Then, in a DITAVal file, you create conditions to include or exclude ‘tagged’ content. You apply the DITAVal file to your publishing job to produce conditionalized output.
Organizing Reusable Content
If organized incorrectly, reuse can give you a headache. I mean, a nasty headache. To sleep well and avoid headaches, always reuse your content from a warehouse topic or “single source of truth”. This is especially important when you reuse content below the topic level, for example, a paragraph.
The rule of thumb is: avoid spaghetti code! Spaghetti code is created when you reuse content from a topic that is not a warehouse topic. As a result, it’s easy to forget which topic is the source of reuse. When you don’t know that, you’re likely to accidentally delete or modify an element that is reused in other places, making your content incomplete. To avoid it, always keep your reusable content in a dedicated file and reuse from there. As a result, there’s no spaghetti code, your content is safe and easy to maintain, and you don’t need to worry about nasty headaches.
Reuse and Localization
Since we’re talking reuse, it’s a must to mention localization because your approach to reusing content may impact the translatability of your content. In other words, if not organized well, reuse can significantly increase your localization costs or even make parts of your content untranslatable. There are a few very important rules you need to remember when reusing content that needs to be localized:
- Whenever possible reuse block elements, for example, paragraphs or steps. Don’t reuse parts of content inside an element, for example, part of a sentence.
- If you need to reuse content inline, reuse whole sentences only.
- If you need to reuse parts of sentences, for example, as variables, make sure that they won’t need to be localized or that they won’t trigger localization issues. Variables are localized separate from the rest of your content, so any terms that need the context of the sentence to localize could result in issues. For example, inflection and word gender in other languages can affect localization if you reuse a noun. On the other hand, proper nouns, which often should not be translated, are a good candidate for variables.
Reuse Strategies
Typically, reuse strategies include a combination of some or all of the above mechanisms. There’s no one golden reuse strategy to follow. It really depends on the nature of your content, product requirements, audience needs, output types, tool limitations, team know-how, and more. Make sure that your reuse strategy is clear, follows the localization and reuse organization guidelines, and is applied consistently by everyone on your team. This will require some consideration and time prior to implementing your reuse strategy. But it’s worth it. Remember, you want to avoid nasty headaches, right?
These are not all of the reuse mechanisms DITA offers. We've discussed only the most common ones. Heretto supports all DITA reuse mechanisms. Let us know if you’d like us to write a post on exemplary reuse strategies or any other aspects of reuse. We’ll gladly do that!


