
Heretto Blog
Stay up to date with industry trends and thought leadership
Featured Blogs


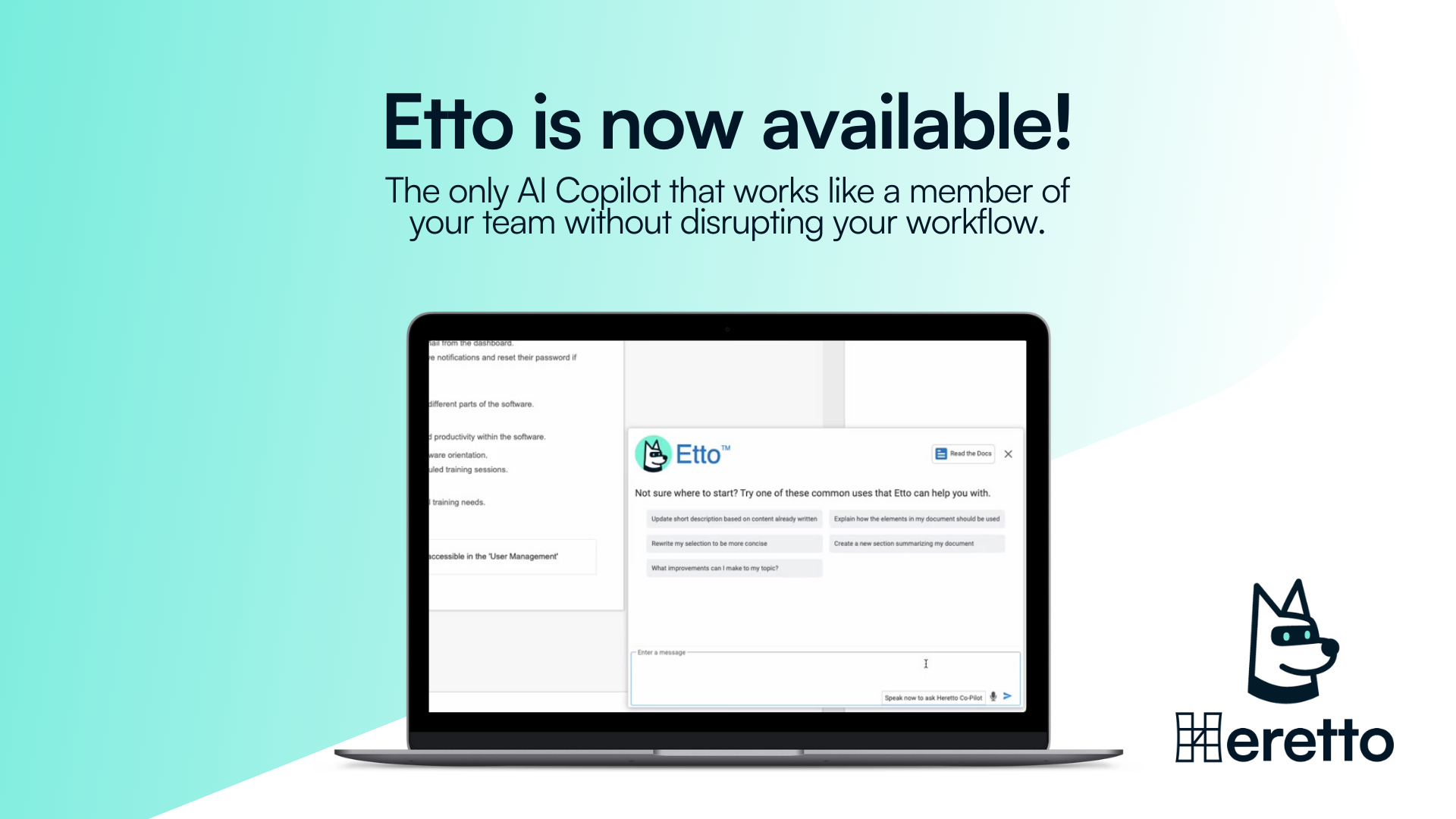
Featured Whitepaper
.png)
All Posts
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.


.png)







Ready to take your content operations to the next level?
Leverage our cutting-edge content operations to deliver exceptional content experiences